推文速览
-
我们优化了复杂靶点处理和对接流程,让「蛋白对接」结果更可靠
-
在「蛋白生成」模块新增 BoltzGen、LigandMPNN、Protenix 三款核心模型
-
蛋白编号现在可直接展开为「蛋白实体卡片」,查看和追溯都更方便
立即体验: https://matvenus.com/
01 蛋白对接:从“跑通”到“跑得准”
做docking,最怕的不是任务跑不起来,而是结果看起来合理,实际并不可靠。
结构预处理是否正确?
关键配体、金属离子和辅因子是否被合理保留?
结合位点是否具有生物学相关性?
不同类型的靶点/配体是否使用了合适的工作流?
最终pose是否真的能支持后续实验决策?
所以这次,我们重点升级了平台的蛋白对接能力,帮你把那些最容易“踩坑”的环节提前考虑进去:
● 更会处理复杂靶点
针对复杂靶点(尤其是含配体或金属离子的体系),提升设计能力与自动化水平
● 更准的对接起点
优化预处理流程和结合位点预测逻辑,让docking从更有生物学相关性的位置开始
● 更合适的工作流
根据靶点的不同类型(纯蛋白、多肽、小分子、含金属的小分子)分别运行各自定制的工作流。目前模型解析到正确工作流的正确率已达95%以上
简单来说,这次升级解决的不是“能不能跑通”的问题,而是进一步解决:蛋白对接跑得对不对,结果靠不靠谱。
02 蛋白生成:新增三款核心模型
为了进一步提升蛋白生成任务的场景覆盖、候选质量和筛选效率,本次更新新增BoltzGen、LigandMPNN、Protenix三款核心模型:
● BoltzGen:增强全新结合蛋白从头设计能力
通过接入BoltzGen,平台将具备面向多类型生物靶标的binder设计能力,可根据蛋白、肽段、小分子等目标生成蛋白、肽、纳米抗体、环肽等候选结合分子,服务于靶点功能调控、蛋白互作干预、分子识别、诊断探针开发及功能验证工具分子构建等场景。
.gif)
● LigandMPNN:提升含配体体系设计精度
LigandMPNN侧重于在给定三维结构约束下进行高精度蛋白序列设计,尤其适合包含小分子配体、金属离子、辅因子、核酸或蛋白相互作用界面的体系,可围绕结合口袋和功能位点优化氨基酸序列,以提升结构稳定性、配体识别和功能位点匹配度。
● Protenix:补强通用蛋白设计能力
Protenix可用于预测蛋白、DNA/RNA、小分子配体、离子等多组分体系的三维结构,并进一步解析分子间的结合构象与相互作用界面。相比平台此前已经接入的AlphaFold2、ESMFold,主要解决蛋白序列到蛋白结构的问题,Protenix 更适合处理蛋白-配体、蛋白-核酸、抗原-抗体、蛋白复合物、含离子/辅因子体系等多组分场景。接入后,平台不仅能预测蛋白本身长什么样,还能帮助用户判断不同分子之间如何结合、界面在哪里、构象是否合理、是否适合进入后续设计或实验验证。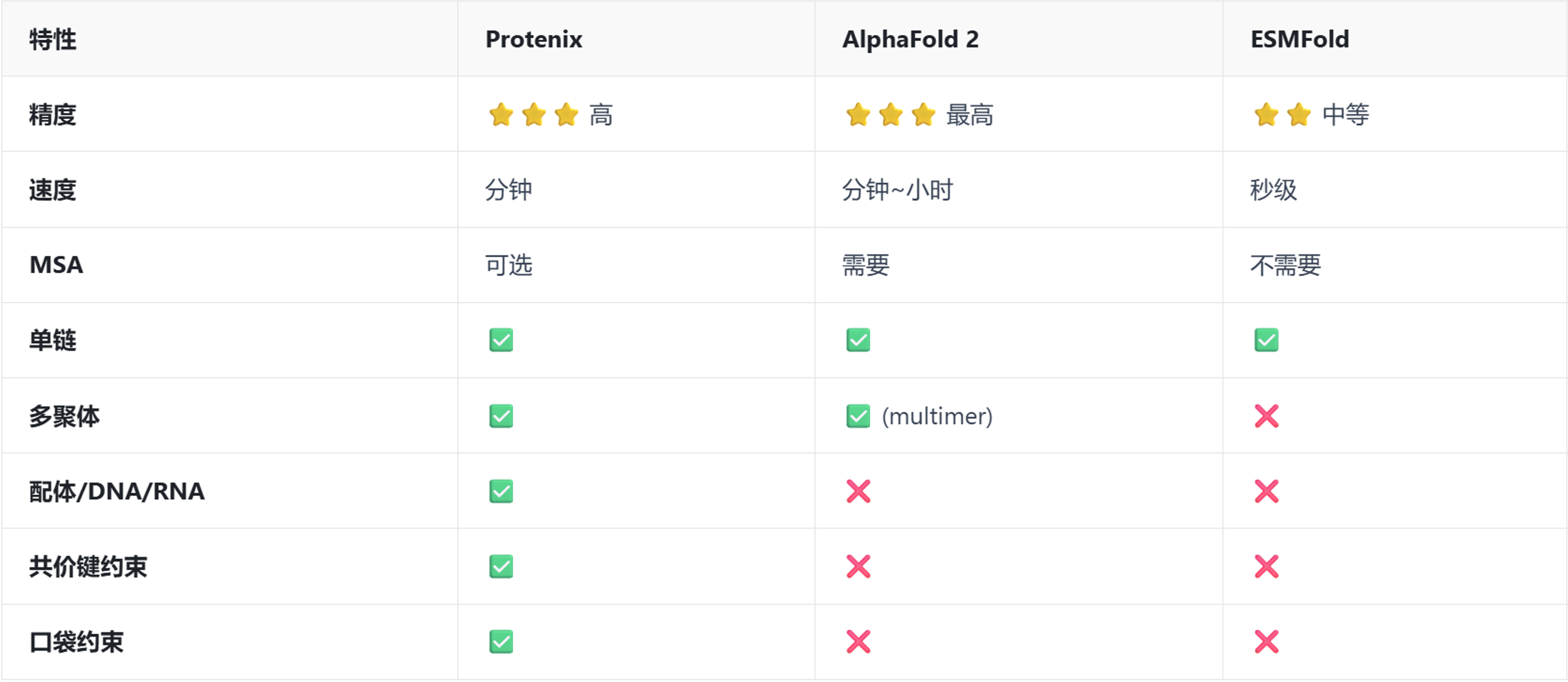
三大引擎对比
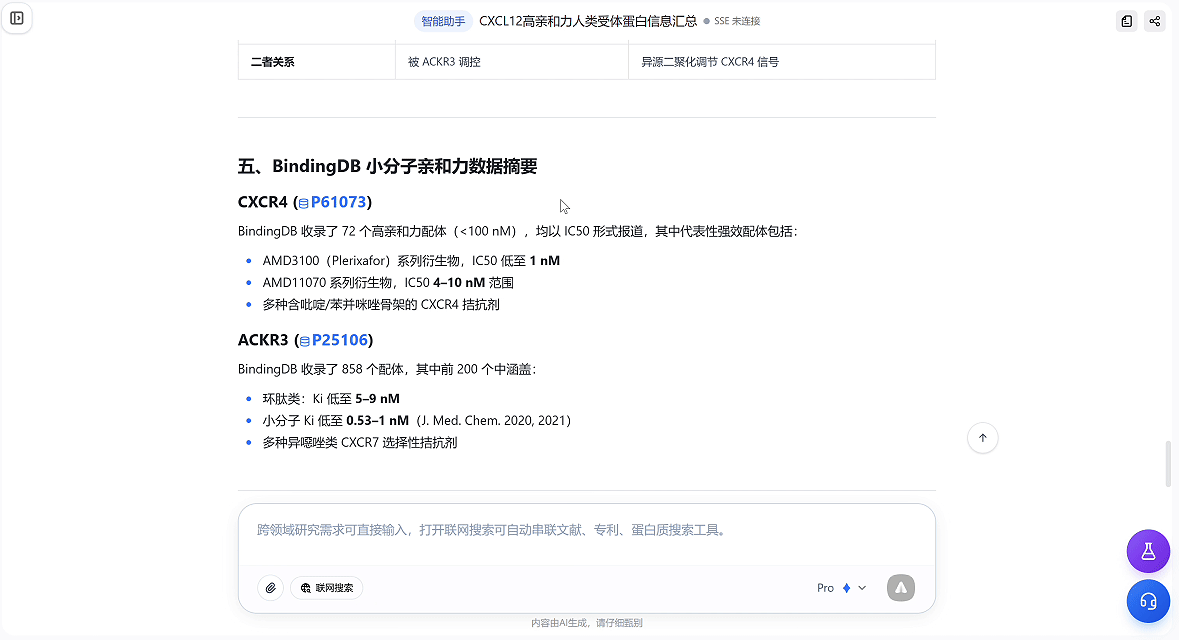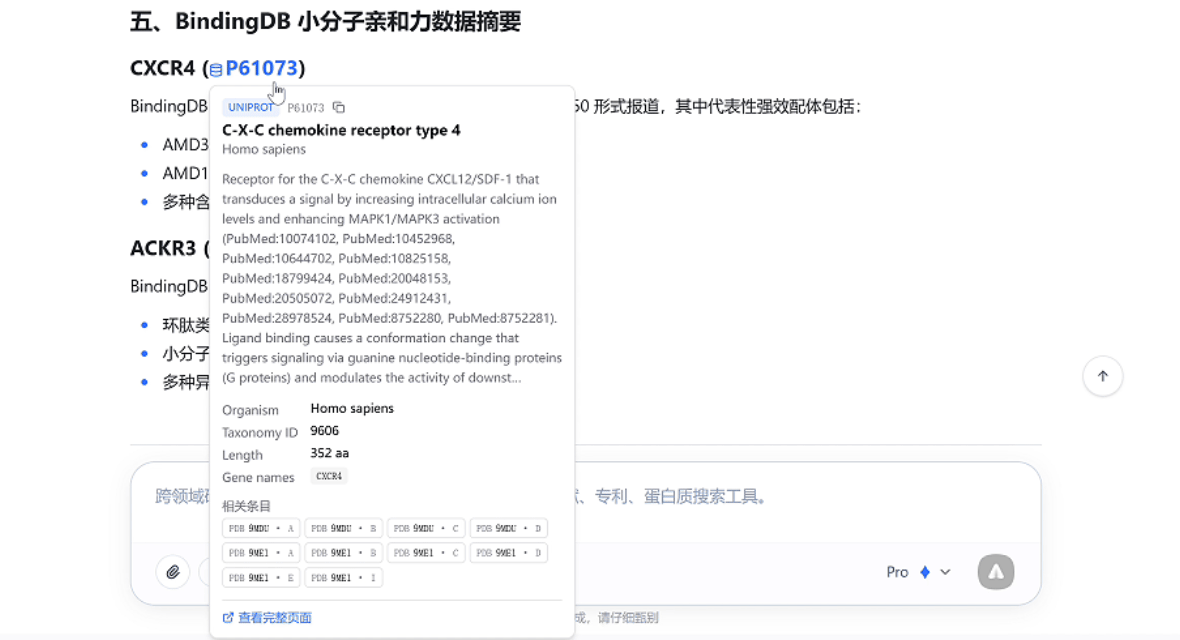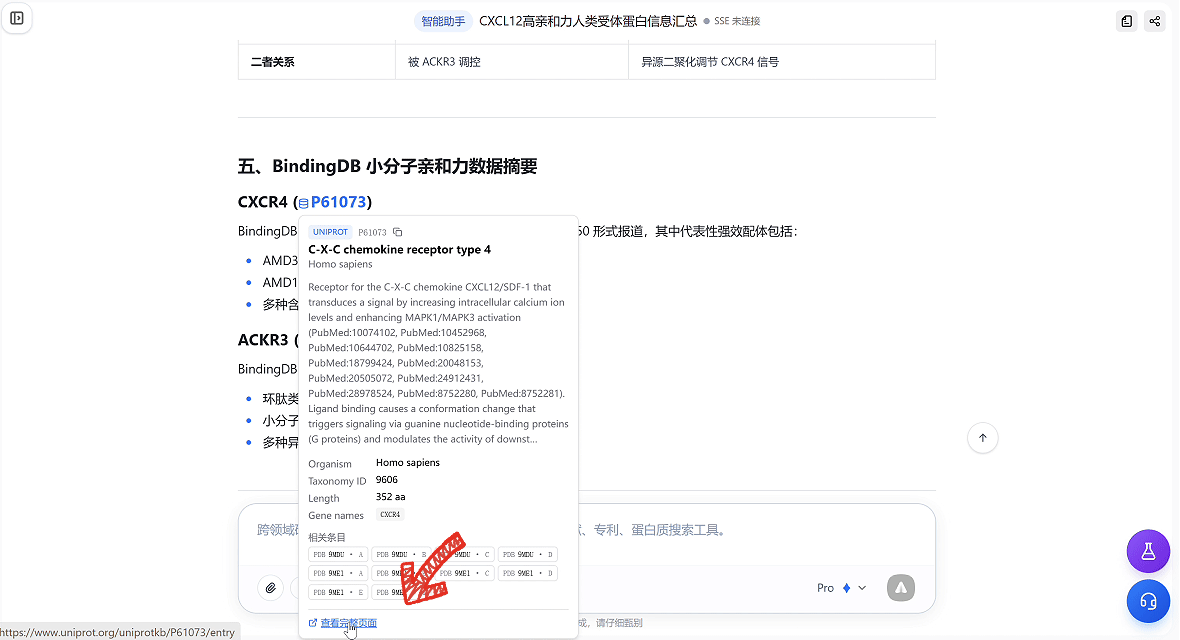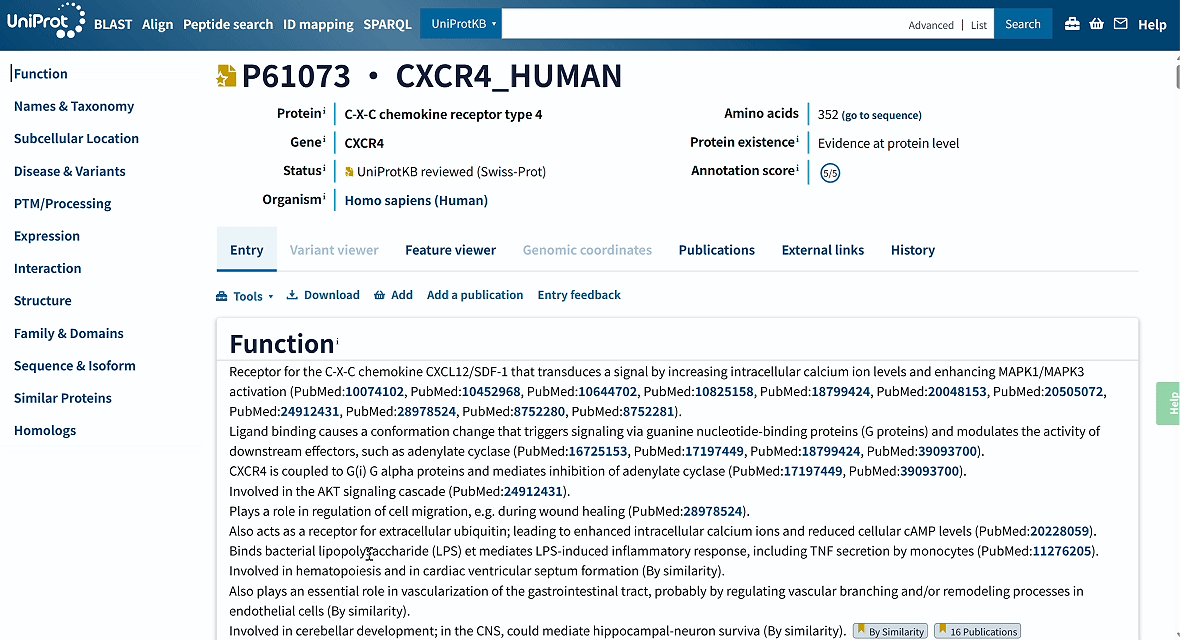
03 蛋白实体卡片:关键信息一键查看
为了让蛋白信息查起来更顺手,本次更新新增「蛋白实体卡片」功能。以后在平台中看到带有蓝色标识的蛋白编号,直接点一下,就能查看对应数据库里的关键信息。如果想继续深挖,也可以点击卡片下方「查看完整页面」,一键跳转到数据库原链接。
● 信息查看更高效
名称、来源、功能注释等关键信息,均会在卡片中直接展示
● 后续查证更方便
支持一键跳转数据库原链接,方便进一步查看完整信息
目前,平台能够调用的大部分生物研究常用数据库(如Uniprot、PDB、GO等)的检索结果,都已经支持此项功能。
MatwingsVenus™(晓鹜™)正在持续迭代,
希望把更多真实科研场景中的复杂问题,
变成平台中更顺畅、更可靠的功能体验。
欢迎随时添加官方客服反馈使用体验,
优质建议有机会获得积分福利喔~